
LLMのトレーニング向けデータセット準備方法
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんちには。
データ事業本部 インテグレーション部 機械学習チームの中村( @nokomoro3 )です。
今回は、LLM(大規模言語モデル)のトレーニング向けにデータセットを準備する方法について解説します。
データセットの種類と準備
一般的に現在のLLM(大規模言語モデル)の学習は、自己回帰型言語モデル(Causal Language Model, CLM)として設計されており、次のトークンを予測するタスクを通じて学習されることが多くなっています。
事前学習用データセット
自己回帰型言語モデルの学習は、自己教師有学習としてトレーニングが可能です。
そのため通常ラベル付けは必要なく、あるまとまったドキュメント(コーパス)を準備すれば学習することが可能となっています。
実際事前学習では、wikipediaなどのコーパスを準備することで学習が可能です。
教師ありデータセット(SFTデータセット)
ただしChatGPTのように、LLMを特定のタスク(例: 質問応答)に適応させるためには、教師有データセット使用して学習する必要があります。
これらのデータセットをSFT(Supervised Fine-Tuning)データセットと呼ぶことがあります。
SFTデータセットを使った学習あっても、実際には事前学習と同じく次のトークンを予測する問題として学習を行います。
質問・応答のデータを使って、以下のような特殊トークンで構成される一つのシーケンスを作成します。
BOS
[INST]
<<SYS>>
{いわゆるシステムプロンプトがあればここに入れる}
<</SYS>>
{ユーザからのQuestionをここに入れる}
[/INST]
{正解の回答をここに入れる}
EOS
そして、回答部分のみを学習時の損失計算の対象にすることで、チューニングを行います。
データセットのまとめページ
事前学習、SFTともに使用可能なデータセットは以下にまとまっています。
今回の記事もここから使用するデータセットを探しています。
LLM学習の手順
一般的にLLMの学習は以下の手順が必要となります。
- テキストデータセットの準備
- モデルに合ったトークナイザでテキストをエンコード
- ラベルデータの作成
- データセットをファイルとして保存
この手順に則って、データを準備してみます。
実践: データセットを作成してみる
実行環境
実行環境としてはGoole Colabを使います。
パッケージについてはtransformersなどはインストール済みとなっていますが、datasetsがないためインストールします。
!pip install datasets
バージョン確認の結果は以下です。
!pip freeze | grep -e "^datasets" -e "^transformers"
# datasets==3.2.0
# transformers==4.47.1
トークンの準備
モデル名に合ったトークナイザを取得して使用するため、規約への同意またはトークンの取得が必要です。
以下の記事などをご参考に準備されてください。
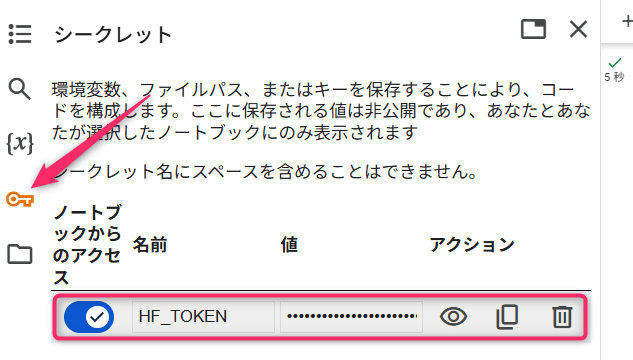
トークンはColabのシークレット機能を使って、HF_TOKENとして設定しておきます。
トークナイザの取得
モデル名を指定して、それに合ったトークナイザを取得します。今回は以下のモデルを使用します。
from transformers import AutoTokenizer
# モデルに合ったトークナイザーを取得
model_name = "meta-llama/Meta-Llama-3-8B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
パティングのトークンを念のため明示的に指定します。
# パディングトークンが設定されていない場合、明示的に設定
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token # 通常、<eos>を<pad>として使う
トークナイズ処理の定義
テキストを分割してさらに数字にエンコードする処理をトークナイズと言います。
こちらを後述のmap関数で処理するために、1サンプル当たりの処理を関数で記載しておきます。
def tokenize(example):
return tokenizer(example["text"], padding="max_length", truncation=True, max_length=4096)
以下に引数の説明を記載します。
padding="max_length": 短い系列をパディングで埋めて最大長に揃える。max_length: トークナイザが生成するトークン列の最大長。truncation=True: 最大長を超えた部分を切り捨てる。
特に max_length の設定値は、モデルのコンテキスト長以下に設定する必要があります。
max_lengthとモデルのコンテキスト長を合わせた場合は、入力を最大限使用することになります。
しかしメモリ使用量が増加したり、長い系列のデータに偏った学習になることとのトレードオフとなりますので、チューニングの要素となりうる点に注意が必要です。
トークナイズの結果としては input_ids と attention_mask というカラムが得られます。
input_ids はエンコードされた数値系列となっており、 attention_mask はその点がpaddingかどうかを表す情報となります。
ラベル列の追加
学習に必要なデータセットとしては input_ids と attention_mask と labels というカラムが必要となります。
次のトークンを予測する問題のラベルとなるため、input_ids と同じ値を labels に入れれば、基本的にはOKです。
実際には input_ids と labels は、labels を後ろに一つシフトする必要があるのですが、自己回帰型言語モデルの学習の場合、モデル内部でそのシフトを実施するので、データとしてずらす必要はありません。
あとは、 attention_mask が0の場合はそこはpaddingであることを示しているので、損失計算の対象外を示すように -100 をラベルに設定しておけばOKです。
def add_labels(example):
example["labels"] = [
-100 if mask == 0 else token_id
for token_id, mask in zip(example["input_ids"], example["attention_mask"])
]
return example
処理の実行
あとは、これらをデータの各splitに対して実行して保存します。
その中で text という元々データセットに含まれるカラムは削除しておきます。(データサイズ節約のため)
from datasets import load_dataset
load_dataset("fujiki/wiki40b_ja", split="train[:10%]")\
.map(tokenize, batched=True)\
.map(add_labels)\
.remove_columns(["text"])\
.save_to_disk("./tokenized_dataset/train")
load_dataset("fujiki/wiki40b_ja", split="validation[:10%]")\
.map(tokenize, batched=True)\
.map(add_labels)\
.remove_columns(["text"])\
.save_to_disk("./tokenized_dataset/validation")
load_dataset("fujiki/wiki40b_ja", split="test[:10%]")\
.map(tokenize, batched=True)\
.map(add_labels)\
.remove_columns(["text"])\
.save_to_disk("./tokenized_dataset/test")
[:10%] は元データの10%を処理するという意味となります。
実行結果
以下のようなファイルが作成されました。
./tokenized_dataset
├── test
│ ├── data-00000-of-00001.arrow
│ ├── dataset_info.json
│ └── state.json
├── train
│ ├── data-00000-of-00008.arrow
│ ├── data-00001-of-00008.arrow
│ ├── data-00002-of-00008.arrow
│ ├── data-00003-of-00008.arrow
│ ├── data-00004-of-00008.arrow
│ ├── data-00005-of-00008.arrow
│ ├── data-00006-of-00008.arrow
│ ├── data-00007-of-00008.arrow
│ ├── dataset_info.json
│ └── state.json
└── validation
├── data-00000-of-00001.arrow
├── dataset_info.json
└── state.json
これをtarに固めてダウンロードして使いましょう。
!tar cvf ./tokenized_dataset.tar ./tokenized_dataset
まとめ
いかがでしたでしょうか。これでデータの準備を行うことができました。
本記事がLLMを学習されたい方の参考になれば幸いです。










